# vLLora - Debug your agents in realtime
> Your AI Agent Debugger
This file contains all documentation content in a single document following the llmstxt.org standard.
## Introduction
Debug your AI agents with complete visibility into every request. vLLora works out of the box with OpenAI-compatible endpoints, supports 300+ models with your own keys, and captures deep traces on latency, cost, and model output.

## Installation
Easy install on Linux and macOS using Homebrew.
### Homebrew (macOS & Linux)
```bash
brew tap vllora/vllora
brew install vllora
```
Launch vLLora:
```bash
vllora
```
This starts the gateway and opens the UI in your browser.
:::tip Homebrew Setup
New to Homebrew? Check these guides:
- [Homebrew Installation](https://docs.brew.sh/Installation)
- [Homebrew on Linux](https://docs.brew.sh/Homebrew-on-Linux)
:::
### Run from Source
Want to contribute or run the latest development version? Clone the [GitHub repository](https://github.com/vllora/vllora) and build from source:
```bash
git clone https://github.com/vllora/vllora.git
cd vllora
cargo run serve
```
This will start the gateway on `http://localhost:9090` with the UI available at `http://localhost:9091` in your browser.
:::tip Development Setup
Make sure you have Rust installed. Visit [rustup.rs](https://rustup.rs/) to get started.
:::
## Send your First Request
After starting vLLora, visit http://localhost:9091 to configure your API keys through the UI. Once configured, point your application to http://localhost:9090 as the base URL.
vLLora works as a drop-in replacement for the OpenAI API, so you can use any OpenAI-compatible client or SDK. Every request will be captured and visualized in the UI with full tracing details.
```bash
curl -X POST http://localhost:9090/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "Hello, vLLora!"
}
]
}'
```
Now check http://localhost:9091 to see your first trace with full request details, costs, and timing breakdowns.
---
## License
vLLora is [fair-code](https://faircode.io/) distributed under the **Elastic License 2.0 (ELv2)**.
By using vLLora, you agree to all of the terms and conditions of the Elastic License 2.0.
## Enterprise
Proprietary licenses are available for enterprise customers. Please reach out via [email](mailto:hello@vllora.dev).
## Full License Text
The complete Elastic License 2.0 text is available at [www.elastic.co/licensing/elastic-license](https://www.elastic.co/licensing/elastic-license).
---
## Quick Start
Get up and running with vLLora in minutes. This guide will help you install vLLora, setup provider and start debugging your AI agents immediately.
## Step 1: Install vLLora
Follow the Installation guide in [Introduction](/docs/#installation) (Homebrew or [Run from Source](/docs/#run-from-source)).
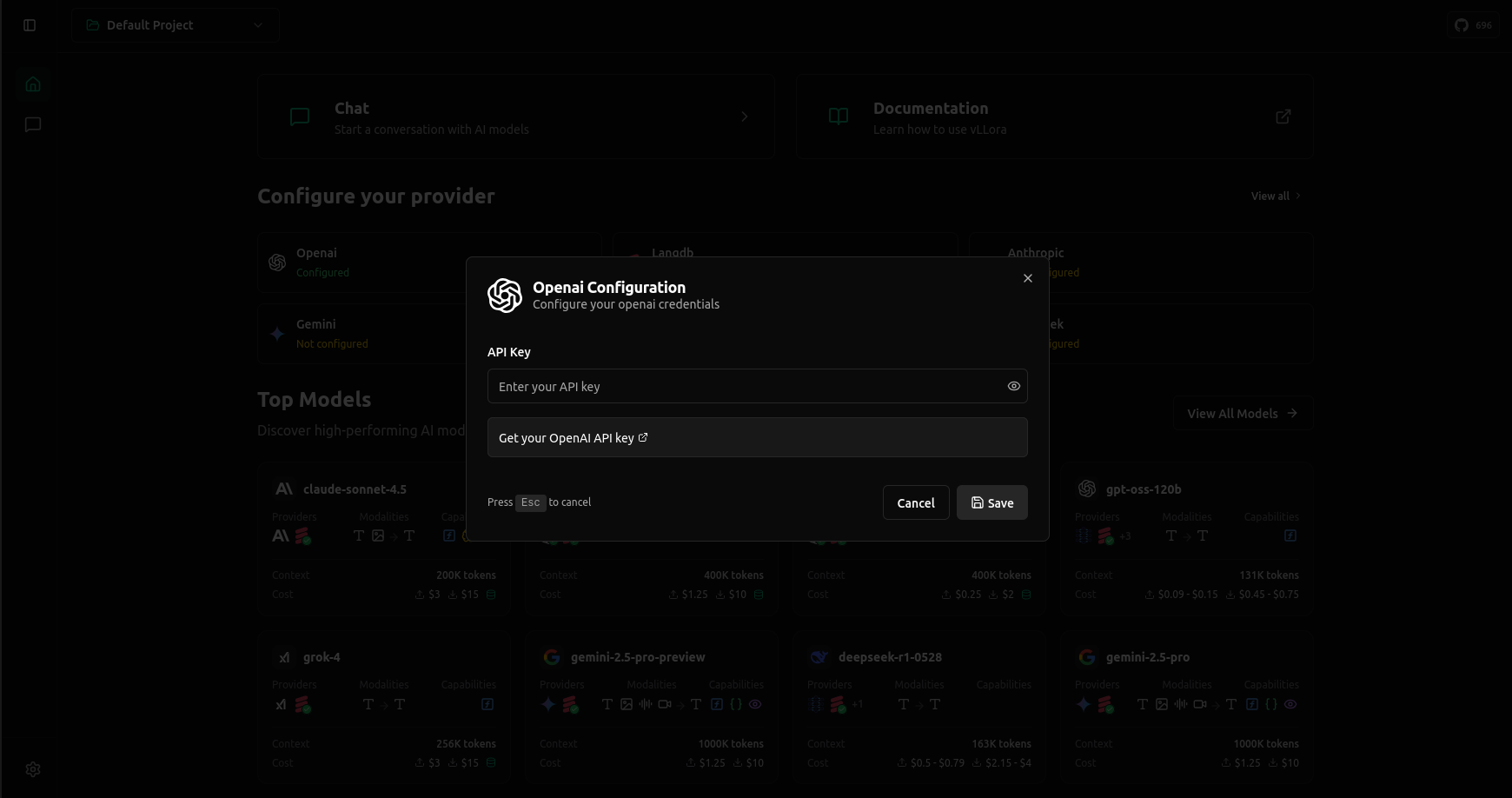
## Step 2: Set up vLLora with the provider of your choice
Let’s take OpenAI as an example: open the UI at http://localhost:9091, select the OpenAI card, and paste your API key. Once saved, you’re ready to send requests. Other providers follow the same flow.
## Step 3: Start the Chat
Go to the Chat Section to send your first request. You can use either the Chat UI or the curl request provided there.

## Step 4: Using vLLora with your existing AI Agents
vLLora is OpenAI-compatible, so you can point your existing agent frameworks (LangChain, CrewAI, Google ADK, custom apps, etc.) to vLLora without code changes beyond the base URL.
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
### Code Examples
```python title="Python (OpenAI SDK)"
from openai import OpenAI
client = OpenAI(
# highlight-next-line
base_url="http://localhost:9090/v1",
api_key="no_key", # vLLora does not validate this token
)
completion = client.chat.completions.create(
# highlight-next-line
model="openai/gpt-4o-mini", # Use ANY model supported by vLLora
messages=[
{"role": "system", "content": "You are a senior AI engineer. Output two parts: SUMMARY (bullets) and JSON matching {service, endpoints, schema}. Keep it concise."},
{"role": "user", "content": "Design a minimal text-analytics microservice: word_count, unique_words, top_tokens, sentiment; include streaming; note auth and rate limits."},
],
)
```
```python title="LangChain (Python)"
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
llm = ChatOpenAI(
# highlight-next-line
base_url="http://localhost:9090/v1",
# highlight-next-line
model="openai/gpt-4o-mini",
api_key="no_key",
temperature=0.2,
)
response = llm.invoke([HumanMessage(content="Hello, vLLora!")])
print(response)
```
```bash title="curl"
curl -X POST \
# highlight-next-line
'http://localhost:9090/v1/chat/completions' \
-H 'x-project-id: 61a94de7-7d37-4944-a36a-f1a8a093db51' \
-H 'x-thread-id: 56fe0e65-f87c-4dde-b053-b764e52571a0' \
-H 'content-type: application/json' \
-d '{
# highlight-next-line
"model": "openai/gpt-4.1-nano",
"messages": [
{"role": "user", "content": "Hello, how are you?"}
],
"stream": true
}'
```
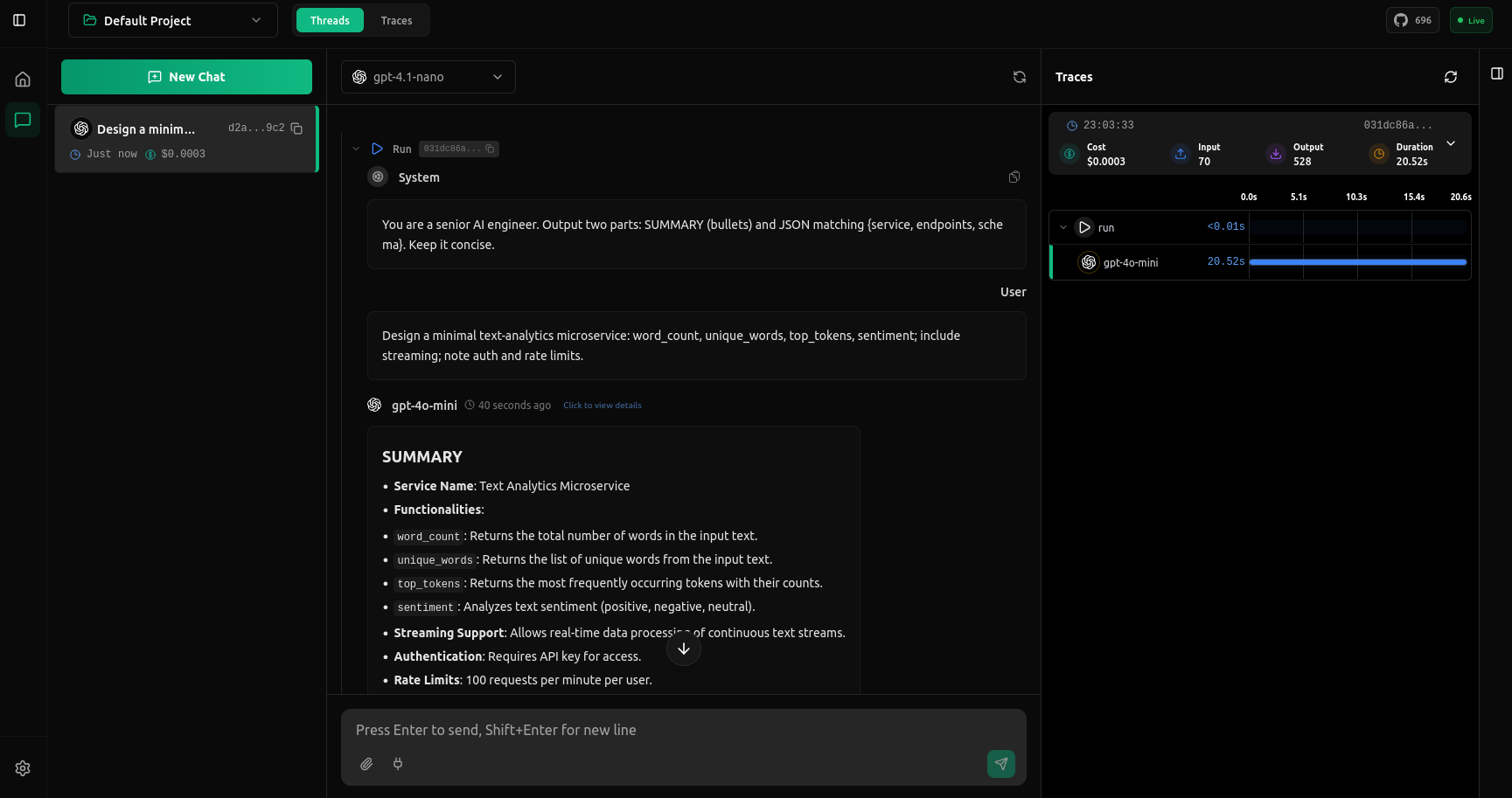
### Traces View
After running, you'll see the full trace.
---
You're all set! vLLora is now capturing every request, showing you token usage, costs, and execution timelines. Click on any trace in the UI to view detailed breakdowns of each step. Keep the UI open while you build to debug your AI agents in real-time.
For more advanced tracing support (custom spans, nested operations, metadata), check out the vLLora Python library in the documentation.
---
## Google ADK
Enable end-to-end tracing for your Google ADK agents by installing the vLLora Python package with the ADK feature flag.

## Installation
```bash
pip install 'vllora[adk]'
```
## Quick Start
Set your environment variable before running the script:
```bash
export VLLORA_API_BASE_URL=http://localhost:9090
```
Initialize vLLora before creating or running any ADK agents:
```python
from vllora.adk import init
# highlight-next-line
init()
# Then proceed with your normal ADK setup:
from google.genai import Client
# ...define and run agents...
```
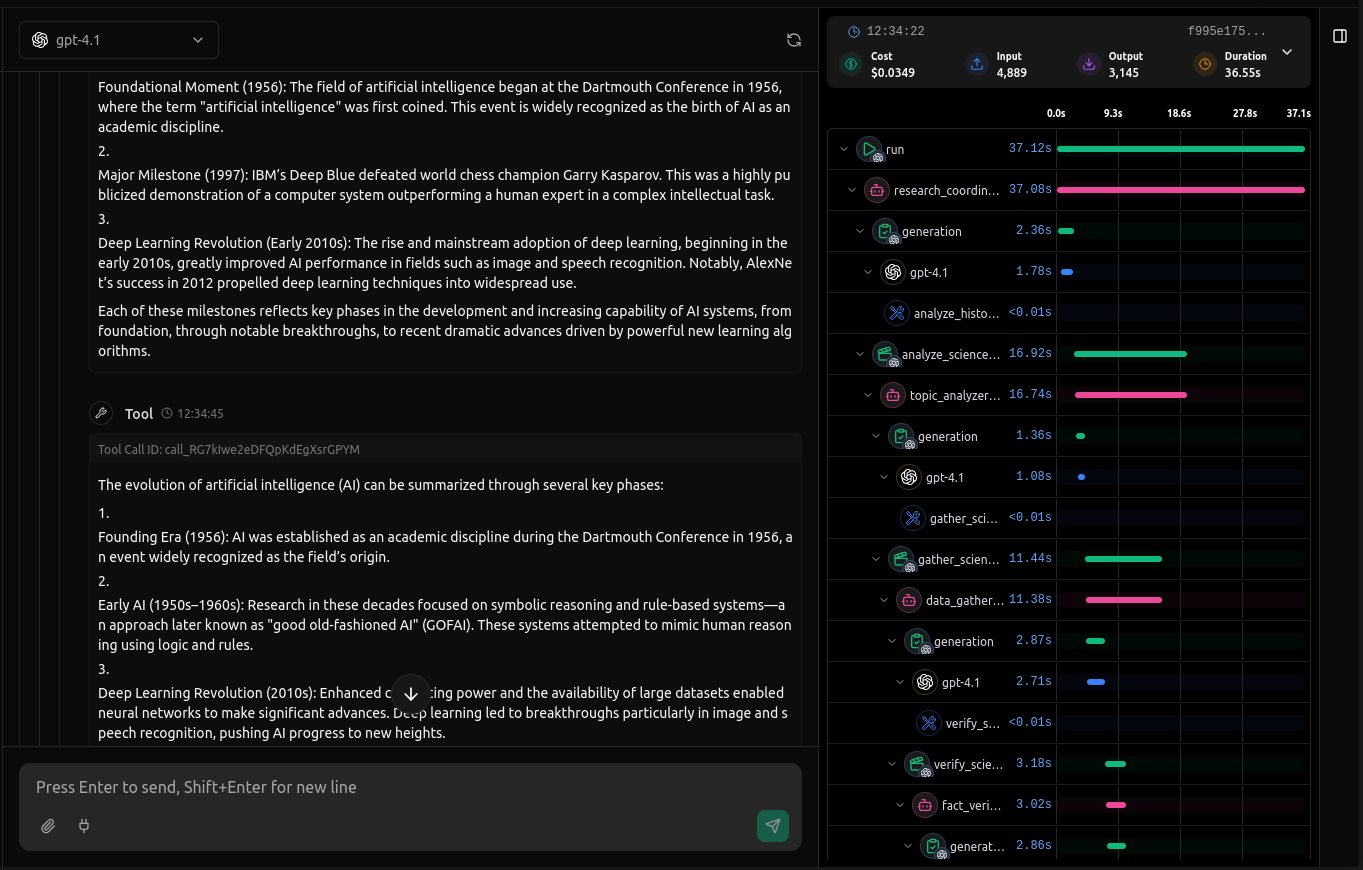
Once initialized, vLLora automatically discovers all agents and sub-agents (including nested folders), wraps their key methods at runtime, and links sessions for full end-to-end tracing across your workflow.
---
## Working with Agent Frameworks
vLLora works out of the box with any OpenAI-compatible API and provides better tracing locally.
However, you can use the **vLLora Python package** with certain agent frameworks to further enhance the tracing experience with deeper integration and framework-specific insights.
## Prerequisites
Install the vLLora Python package for your framework:
```bash
pip install 'vllora[adk]' # For Google ADK
pip install 'vllora[openai]' # For OpenAI Agents SDK
```
## Quick Start
Import and initialize once at the start of your script, before creating or running any agents:
```python
from vllora. import init
init()
# ...then your existing agent setup...
```
This enhances vLLora's tracing with framework-specific details like agent workflows, tool calls, and multi-step execution paths.
**GitHub Repo:** [https://github.com/vllora/vllora-python](https://github.com/vllora/vllora-python)
## Choose Your Framework
import DocCardList from '@theme/DocCardList';
Select a framework above to see detailed integration guides with installation instructions, code examples, and best practices for tracing your agents.
### Coming Soon
Support for additional frameworks is in development:
- **LangGraph**
- **CrewAI**
- **Agno**
## Further Documentation
For full documentation, check out the [vLLora GitHub repository](https://github.com/vllora/vllora-python).
---
## OpenAI Agents SDK
Enable end-to-end tracing for your OpenAI agents by installing the vLLora Python package with the OpenAI feature flag.
## Installation
```bash
pip install 'vllora[openai]'
```
## Quick Start
Set your environment variable before running the script:
```bash
export VLLORA_API_BASE_URL=http://localhost:9090
```
Initialize vLLora before creating or running any OpenAI agents:
```python
from vllora.openai import init
# highlight-next-line
init()
# Then proceed with your normal OpenAI setup:
from openai import OpenAI
# ...define and run agents...
```
Once initialized, vLLora automatically captures all agent interactions, function calls, and streaming responses with full end-to-end tracing across your workflow.