Quickstart
Get up and running with vLLora in minutes. This guide will help you install vLLora, setup provider and start debugging your AI agents immediately.
Step 1: Install vLLora
Follow the Installation guide in Introduction (Homebrew or Build from Source).
Step 2: Set up vLLora with the provider of your choice
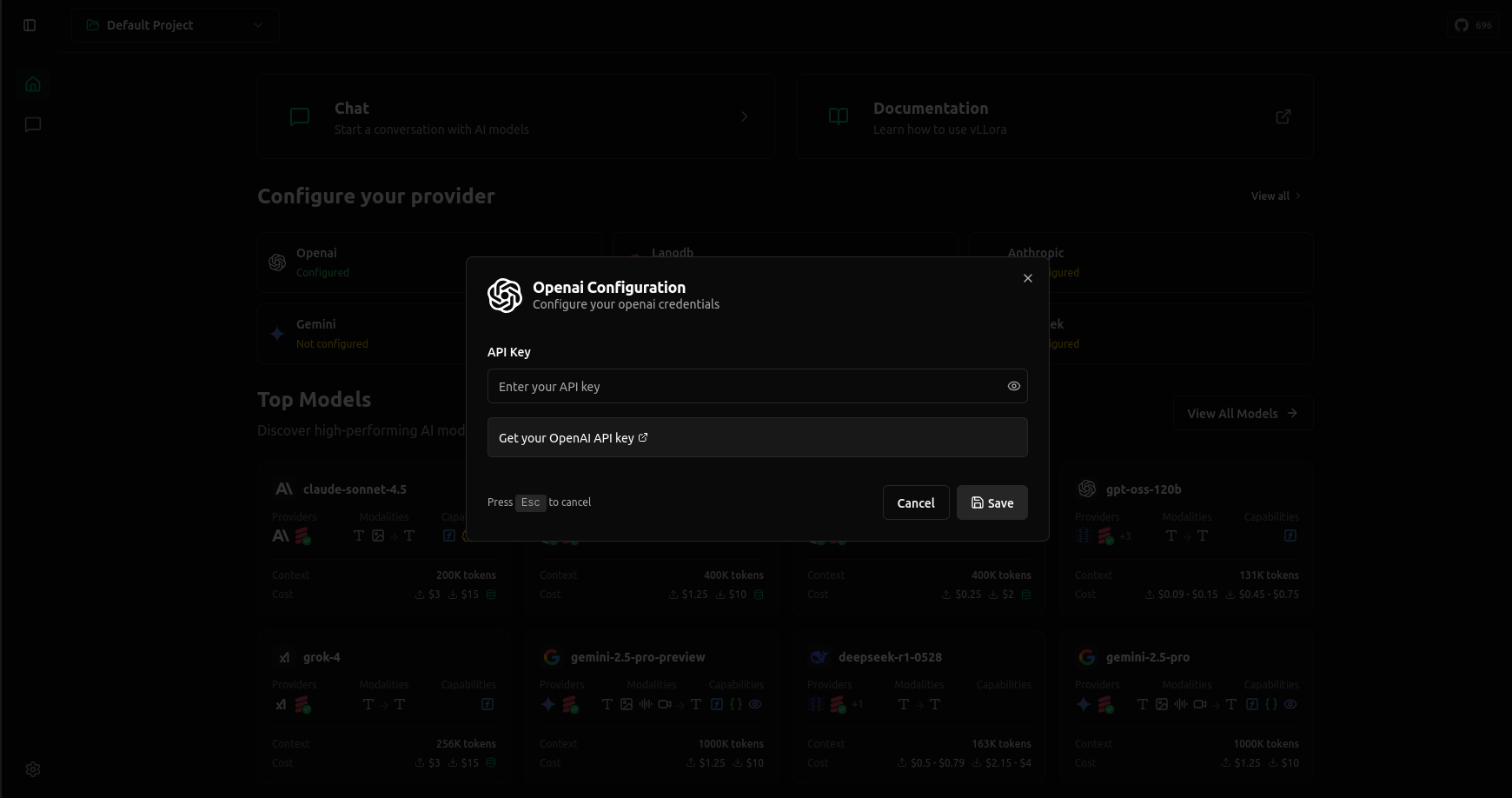
Let’s take OpenAI as an example: open the UI at http://localhost:9091, select the OpenAI card, and paste your API key. Once saved, you’re ready to send requests. Other providers follow the same flow.
Step 3: Start the Chat
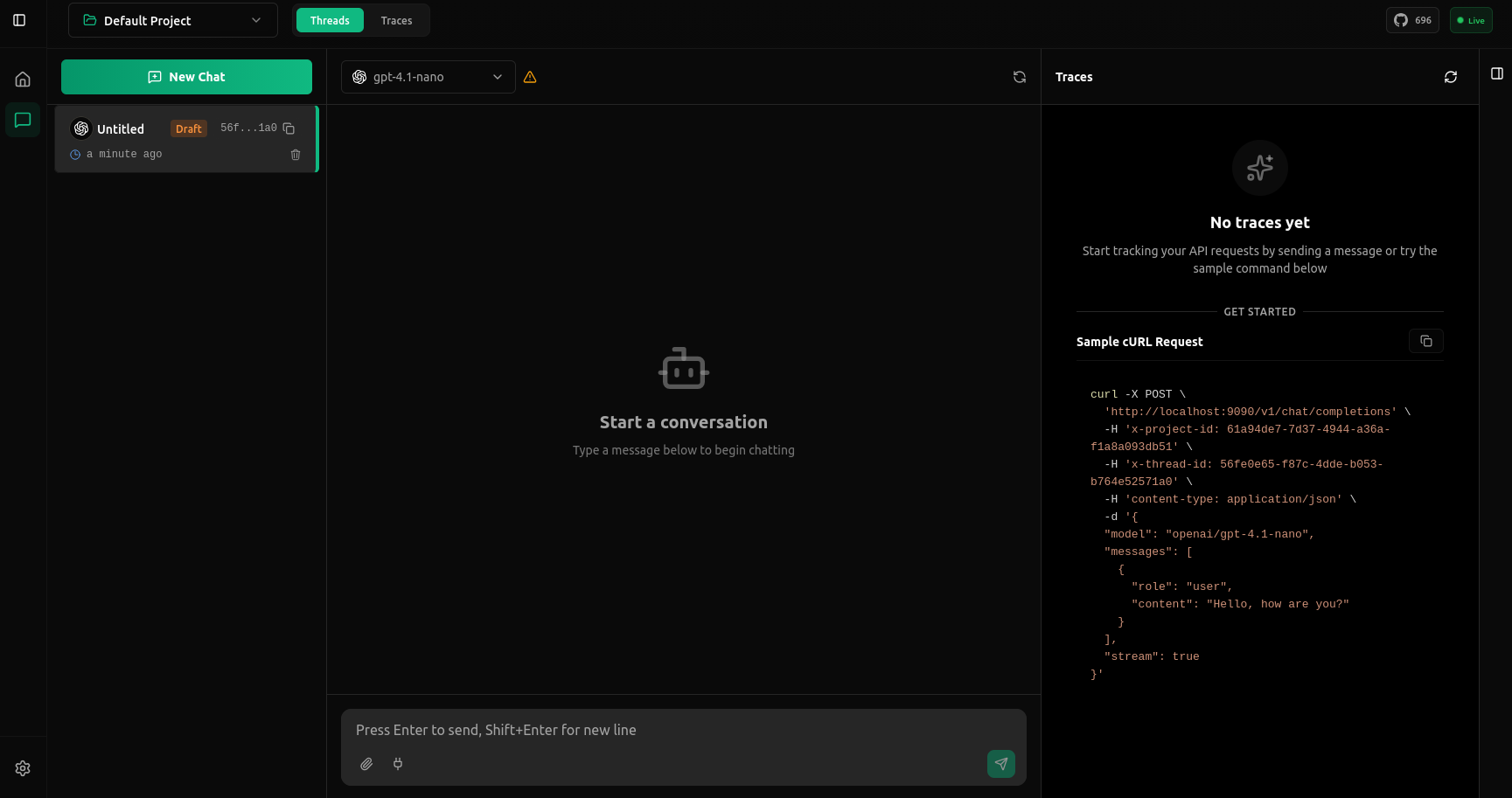
Go to the Chat Section to send your first request. You can use either the Chat UI or the curl request provided there.
Step 4: Using vLLora with your existing AI Agents
vLLora is OpenAI-compatible, so you can point your existing agent frameworks (LangChain, CrewAI, Google ADK, custom apps, etc.) to vLLora without code changes beyond the base URL.
Code Examples
- Python
- LangChain
- curl
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:9090/v1",
api_key="no_key", # vLLora does not validate this token
)
completion = client.chat.completions.create(
model="openai/gpt-4o-mini", # Use ANY model supported by vLLora
messages=[
{"role": "system", "content": "You are a senior AI engineer. Output two parts: SUMMARY (bullets) and JSON matching {service, endpoints, schema}. Keep it concise."},
{"role": "user", "content": "Design a minimal text-analytics microservice: word_count, unique_words, top_tokens, sentiment; include streaming; note auth and rate limits."},
],
)
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
llm = ChatOpenAI(
base_url="http://localhost:9090/v1",
model="openai/gpt-4o-mini",
api_key="no_key",
temperature=0.2,
)
response = llm.invoke([HumanMessage(content="Hello, vLLora!")])
print(response)
curl -X POST \
'http://localhost:9090/v1/chat/completions' \
-H 'x-project-id: 61a94de7-7d37-4944-a36a-f1a8a093db51' \
-H 'x-thread-id: 56fe0e65-f87c-4dde-b053-b764e52571a0' \
-H 'content-type: application/json' \
-d '{
"model": "openai/gpt-4.1-nano",
"messages": [
{"role": "user", "content": "Hello, how are you?"}
],
"stream": true
}'
Traces View
After running, you'll see the full trace.
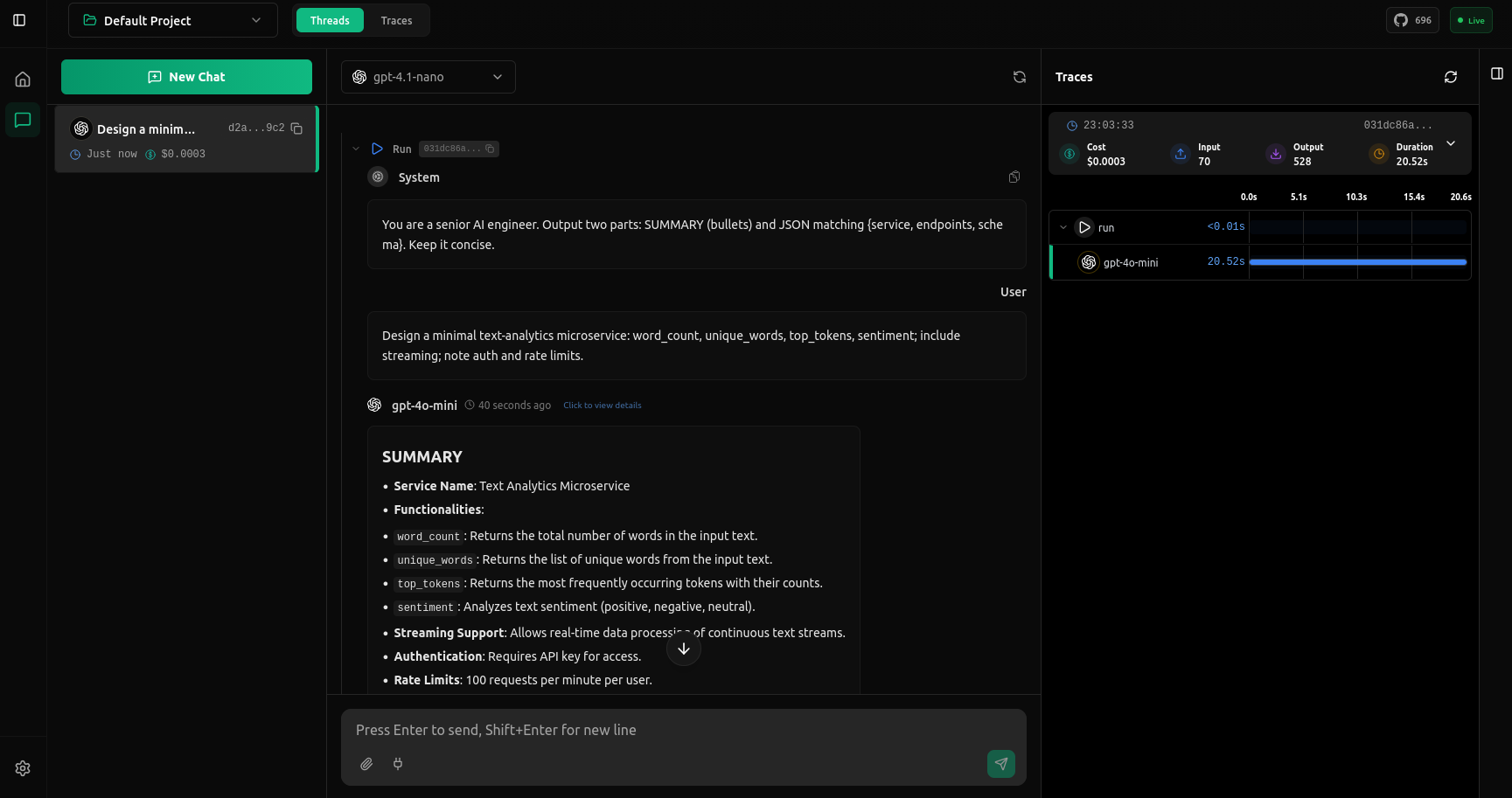
You're all set! vLLora is now capturing every request, showing you token usage, costs, and execution timelines. Click on any trace in the UI to view detailed breakdowns of each step. Keep the UI open while you build to debug your AI agents in real-time.
For more advanced tracing support (custom spans, nested operations, metadata), check out the vLLora Python library in the documentation.