Using vLLora to debug Agents

Building AI agents is hard. Debugging them locally across multiple SDKs, tools, and providers feels like flying blind. Logs give you partial visibility. You need to see every call, latency, cost, and output in context without rewriting code.
Why debugging agents is hard
When you debug locally, requests disappear into SDKs. You piece together prints, partial logs, and guesswork. When something breaks or slows down, pinpointing the step, model, or tool is hard. Cost tracking is manual at best.
Meet vLLora
vLLora is a local debugging tool with a UI that intercepts LLM requests. It implements the OpenAI API, so your existing clients and frameworks work unchanged. Set base_url to http://localhost:9090/v1 and run your code as-is. vLLora forwards requests to your chosen provider using your keys, preserves streaming and tool/function calls, and records a trace for each step.
Get started in under a minute
Install vLLora, point your SDK to it, and keep your existing code:
brew tap vllora/vllora
brew install vllora
vllora
Change your base URL and you're done:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="http://localhost:9090/v1",
model="openai/gpt-4o-mini",
)
Every request now flows through vLLora. Open http://localhost:9091 to see the traces streaming in real time. For detailed setup instructions across different frameworks, see Using vLLora.
Observe your agent in real time
Open the UI while you build. Each request shows inputs, outputs, timing, and cost. No custom logging code needed.
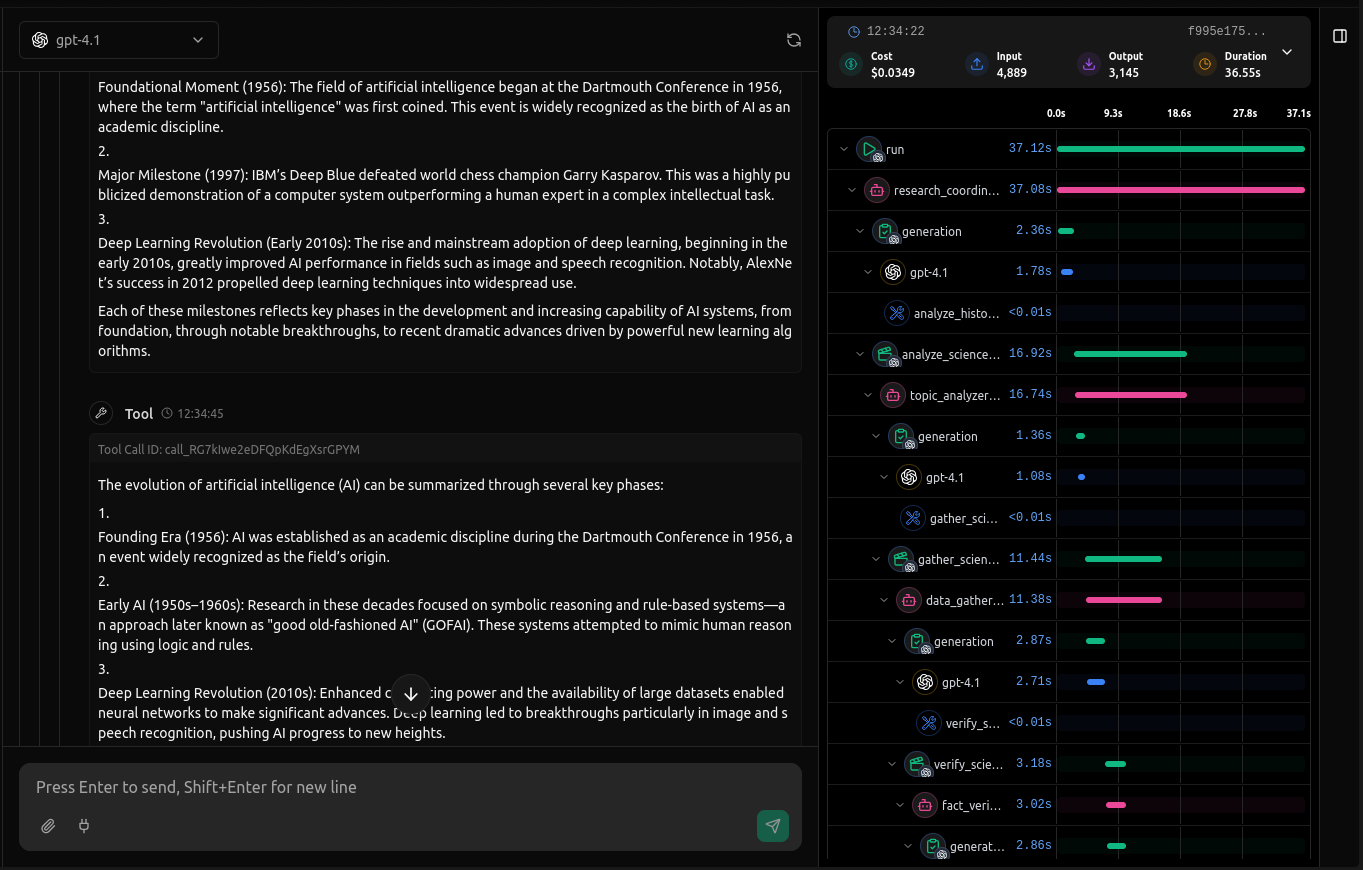
How debugging works
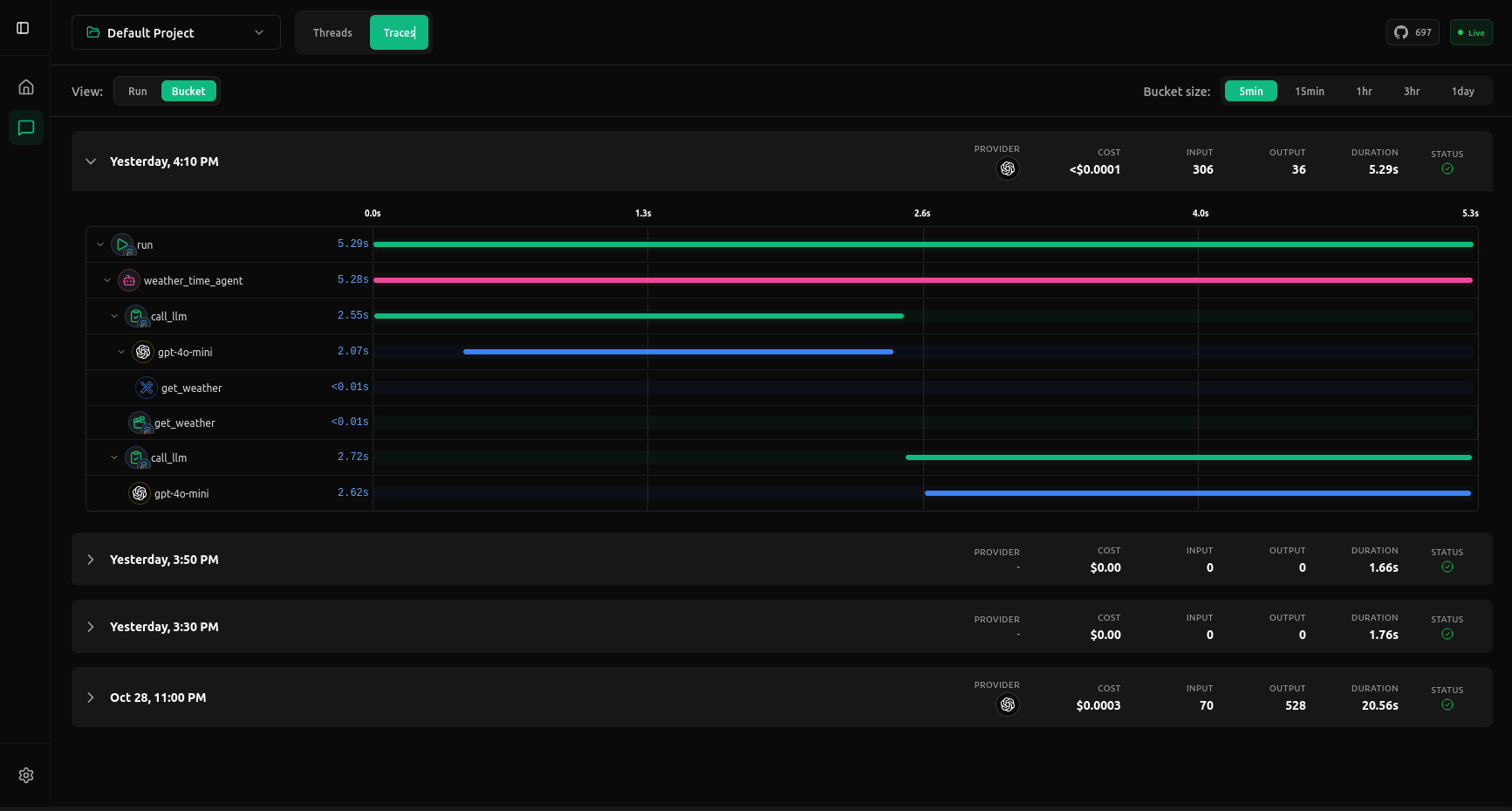
vLLora sits between your SDK and the provider, capturing every request your framework makes and streaming traces to the UI in real time. You get full visibility into inputs, outputs, latency, and cost per model call. Requests are grouped by run or time bucket so you can see how your agent behaves step by step, replay turns, inspect streaming output, or compare model responses across different calls.
Compatibility and models
vLLora works out of the box with OpenAI-compatible clients and major agent frameworks (LangChain, Google ADK, OpenAI Agents). Keep your code, just change the base URL. Use your own provider keys and switch between 300+ models to compare quality, performance, and cost.
When to use vLLora
vLLora shines when you're building agents that use multiple tools and models, measuring latency and cost per step matters, or you're switching between providers like OpenAI, Anthropic, and Gemini and need consistent logs across all of them. If you're debugging chain-of-thought issues or tracking down missing tool calls, vLLora gives you a single pane of glass to see everything that's happening.
Next steps
Ready to dive deeper? Check out the Quickstart for installation details and sending your first trace, or explore Working with Agent Frameworks for deeper integration with frameworks like OpenAI Agents SDK and Google ADK. For a complete overview of the product and setup details, see the Introduction.
You now have x-ray vision for your agents. Build, trace, and optimize faster, all without touching your code.