Debugging LiveKit Voice Agents with vLLora

Voice agents built with LiveKit Agents enable real-time, multimodal AI interactions that can handle voice, video, and text. These agents power everything from customer support bots to telehealth assistants, and debugging them requires visibility into the complex pipeline of speech-to-text, language model, and text-to-speech interactions.
In this video, we go over how you can debug voice agents built using LiveKit Agents with vLLora. You'll see how to trace every model call, tool execution, and response as your agent processes real-time audio streams.
Setup
Run and configure vLLora locally. Follow the Quickstart guide to get started.
brew tap vllora/vllora
brew install vllora
vllora
In your LiveKit Agent code, configure your LLM provider to use vLLora's endpoint:
from livekit.plugins import openai
import os
session = AgentSession(
llm=openai.LLM(
model="model-name",
base_url="http://localhost:9090/v1", # vLLora endpoint
api_key="no_key" # vLLora doesn't validate API keys
),
# ... stt, tts, etc ...
)
What vLLora Shows You
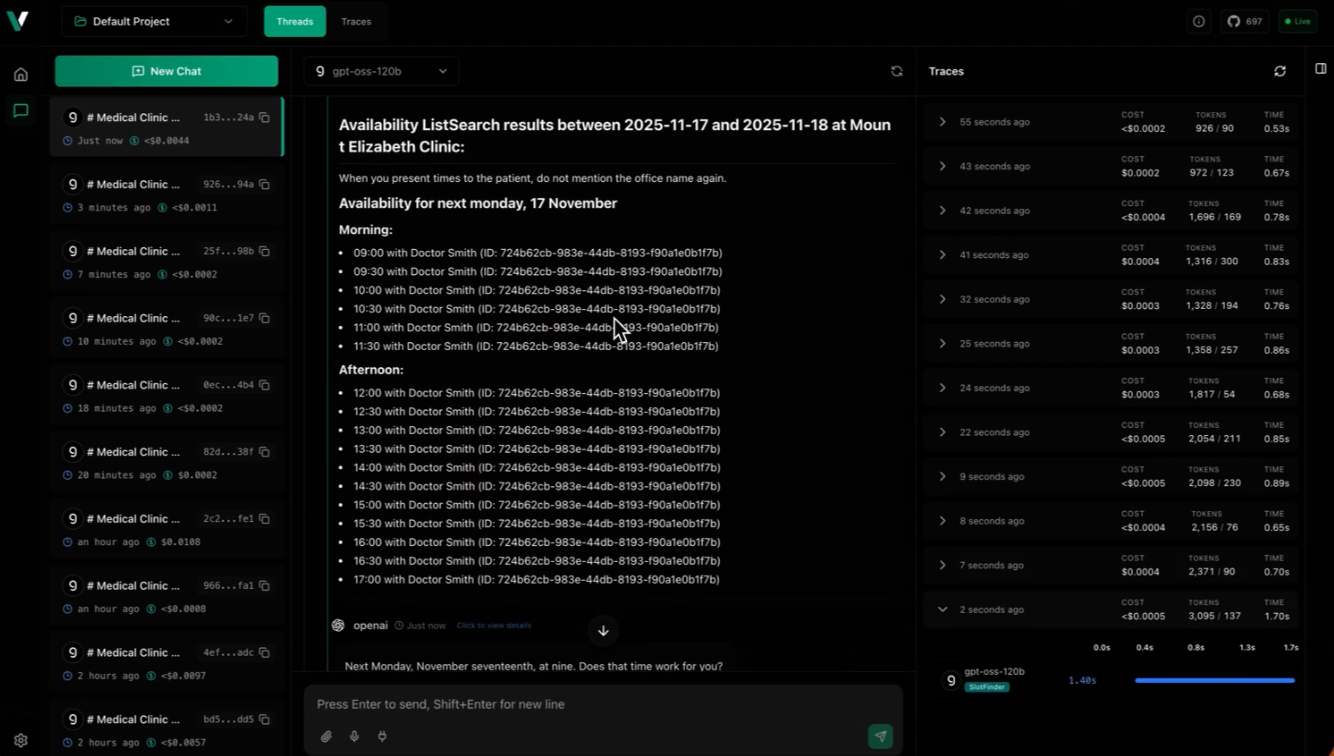
With vLLora running, you can see:
- Model Calls: Every LLM model call with complete input/output, token usage, cost, and timing information
- Tool Definitions: All tools available to your agent, including their schemas and descriptions
- Tool Usage: Every tool call made by the agent, including parameters and responses
By providing complete visibility into your voice agent's execution, vLLora makes it easier to build reliable, performant voice AI applications with LiveKit Agents.