Introducing Lucy: Trace-Native Debugging Inside vLLora
· 5 min read

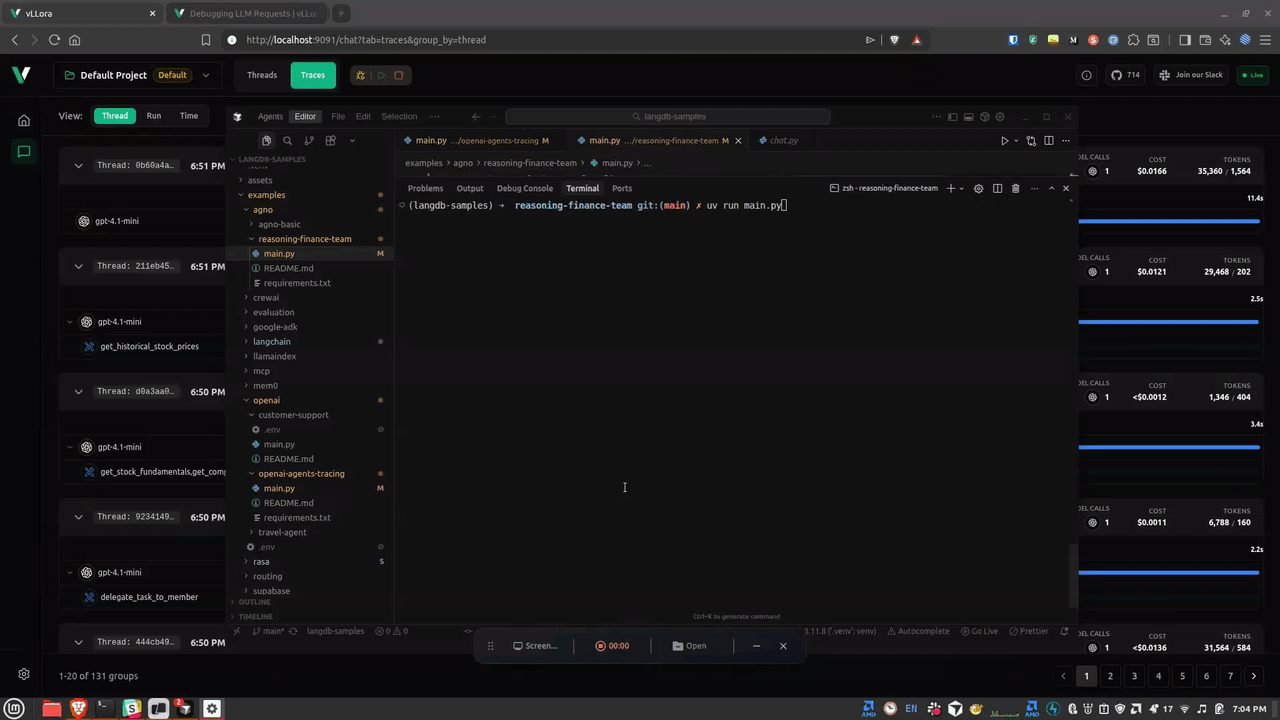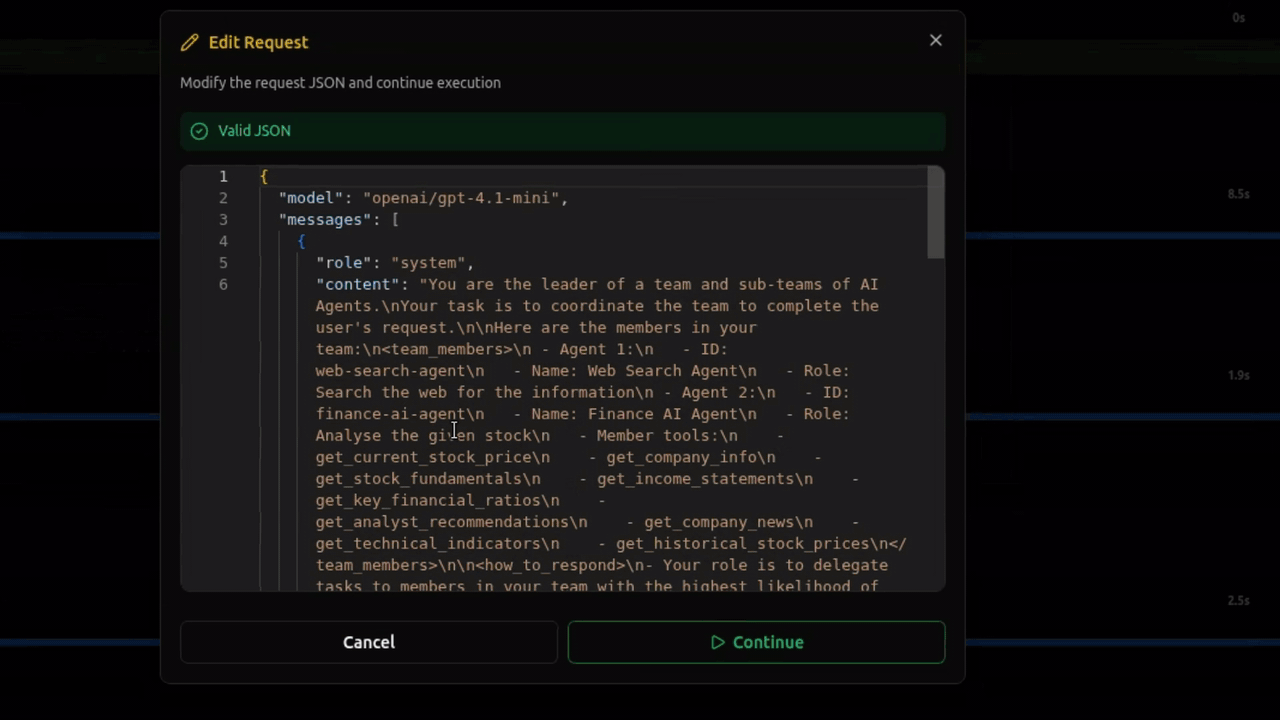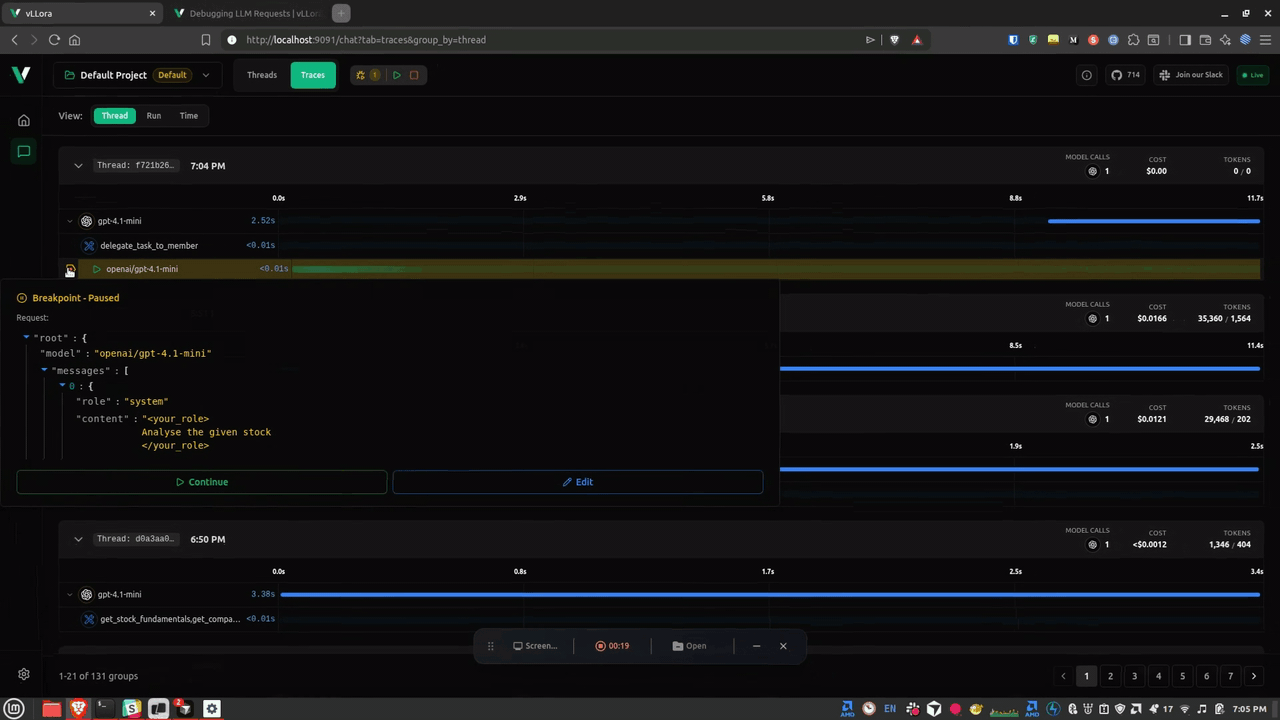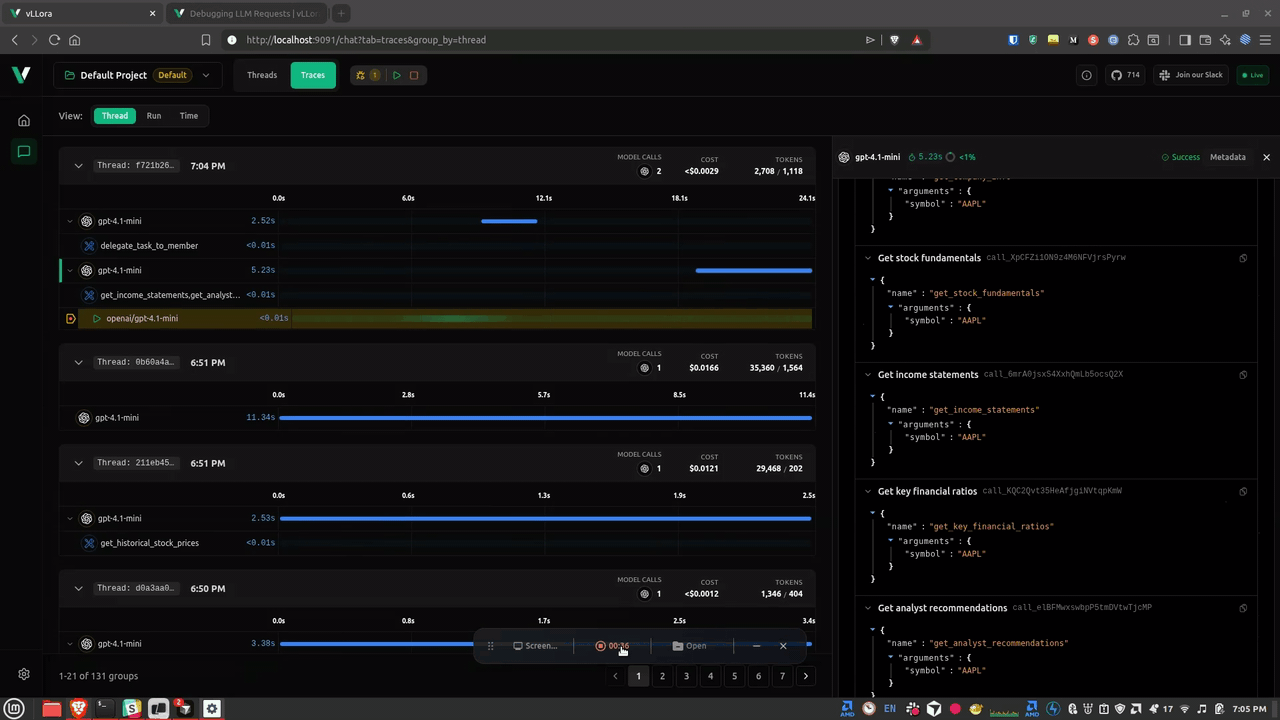
Your agent fails midway through a task. The trace is right there in vLLora, but it's 200 spans deep. You start scrolling, scanning for the red error or the suspicious tool call. Somewhere in those spans is the answer, but finding it takes longer than it should.
Today we're launching Lucy, an AI assistant built directly into vLLora that reads your traces and tells you what went wrong. You ask a question in plain English, Lucy inspects the trace, and you get a diagnosis with concrete next steps. Lucy is available now in beta.